

O ChatGPT foi lançado no final de novembro de 2022 e rapidamente impressionou o mundo com seu desempenho incrível. O aplicativo gerador de textos conseguiu enganar muitos leitores, mesmo os mais atentos, que não conseguiam distinguir os textos produzidos pela inteligência artificial (IA) daqueles escritos por humanos. Mas como é que o que muitos pensavam ser impossível ontem se transformou em realidade tão rapidamente?
“A explicação para esta rápida ascensão da IA e do ChatGPT pode ser vista como um triângulo com todos os três vértices de igual importância. Primeiro, o poder computacional dos computadores aumentou dramaticamente. Em segundo lugar, a quantidade de dados de alta qualidade necessários para treinar redes neurais aumentou. Terceiro, houve muitas inovações na engenharia de redes neurais Nicolas Doyon.
Nicolas Doyon, professor do Departamento de Matemática e Estatística e investigador do Centro de Investigação CERVO, explicou o surgimento da IA e do ChatGPT na sua palestra “Segredos Matemáticos do ChatGPT”.
A convite de Conclusão da educação Da Faculdade de Ciências e Engenharia para apresentar uma conferência ao público em geral sobre este tema, este professor do Departamento de Matemática e Estatística e investigador em Centro de Pesquisa ServoEle discutiu alguns dos marcos na história da inteligência artificial e publicou alguns dos princípios científicos e matemáticos dos quais depende o sucesso do famoso aplicativo de computador.
Máquina de xadrez campeã
Uma das maiores conquistas da inteligência artificial remonta a 1996, quando o computador Deep Blue conseguiu derrotar o campeão mundial de xadrez Garry Kasparov. O Deep Blue está programado para criar uma árvore de possibilidades, atribuir um valor às posições finais dos diferentes ramos da árvore e depois determinar o melhor movimento possível.
Essa abordagem, que funcionou bem no xadrez, era menos adequada para o go, cujo tabuleiro forma uma grade 19 x 19 – que oferece muito mais possibilidades de movimento do que o formato 8 x 8 do xadrez. Mesmo para um computador, a árvore de possibilidades tornou-se muito grande. “Por esta razão, os investigadores disseram para si próprios: ‘Esta não é nada parecida com a nossa forma de pensar'”, diz Nicolas Doyon. Como podemos nos inspirar no trabalho do cérebro e dos neurônios humanos para melhorar a inteligência artificial?
Imitação de neurônios
Ao estudar o funcionamento dos neurônios humanos, descobrimos que eles não reagem a todas as mensagens que recebem. A mensagem deve atingir um limiar mínimo para que o neurônio emita os chamados potenciais de ação, que têm sempre a mesma força e o mesmo formato, qualquer que seja a intensidade da mensagem inicial. Esses potenciais de ação são transmitidos ao próximo neurônio através da sinapse. É uma lei do tudo ou nada.
No entanto, as sinapses não são usadas apenas para transmitir informações de um neurônio para outro; A sua flexibilidade desempenhará um papel central na aprendizagem. Na verdade, os pesquisadores observaram que a força da conexão entre as sinapses muda com o tempo. “Simplificando, quanto mais uma sinapse é usada, ou seja, quanto mais ela propaga o potencial de ação para o próximo neurônio, mais forte ela se torna. Podemos ver claramente no microscópio que quando uma pessoa aprende, a espinha dendrítica, que é uma área do neurônio torna-se maior. Em suma, à medida que a sinapse se torna maior e mais forte, a sinapse ajusta gradualmente a maneira como pensamos.
Como esses fatos biológicos podem ser representados matematicamente? Nicolas Doyon responde: “Uma maneira de traduzir a lei do tudo ou nada para a matemática é usar a função de Heaviside.” Freqüentemente, em matemática, as funções vão de 0 a 1 continuamente. “Uma função Heaviside, por outro lado, é uma função que tem o valor 0 até que a entrada da função atinja um determinado limite. Então, de repente, vai para 1”, explica ele.
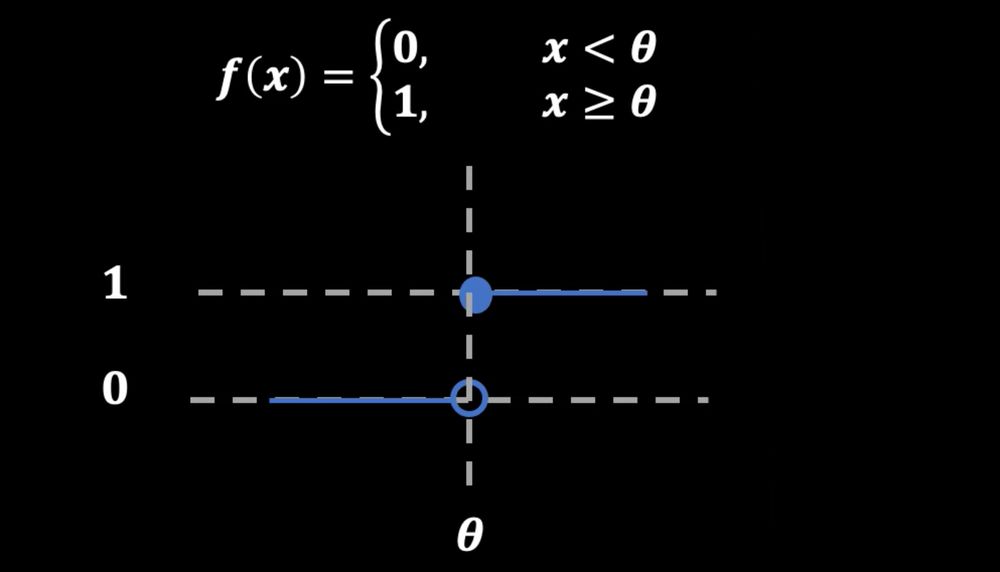
Tudo ou nada pode ser representado matematicamente usando a função de Heaviside.
“Para representar o papel das sinapses, atribuímos pesos às diferentes entradas do neurônio”, acrescenta. Pelo gráfico podemos ver que após determinar os valores numéricos das entradas, multiplicamos esses valores pelo peso do clipe, somamos os resultados dessas multiplicações para obter uma soma ponderada e, por fim, vemos se este valor atinge o limite desejado, o que resultará em 0 ou 1.
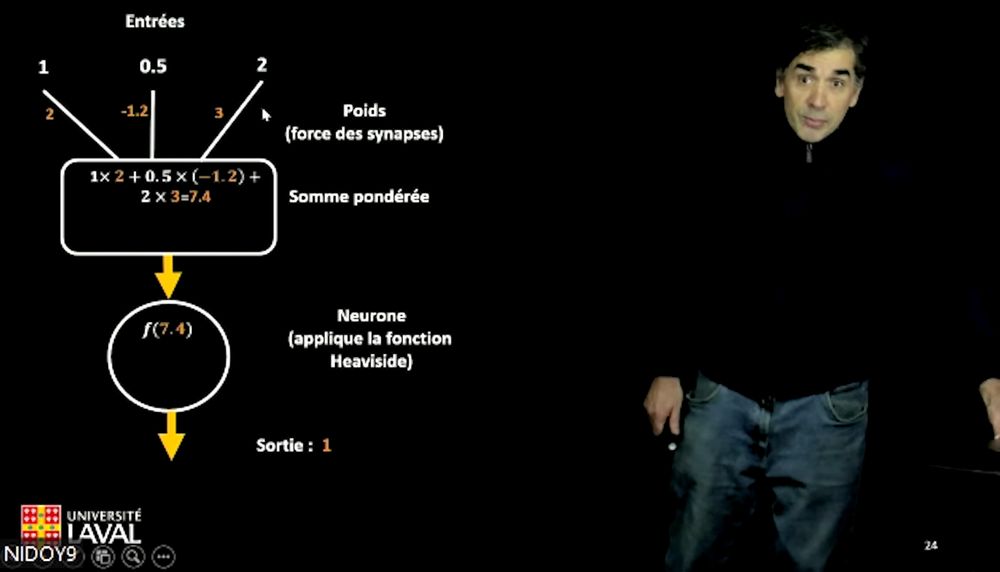
“Para representar o papel das sinapses, atribuímos pesos a diferentes entradas dos neurônios”, explica o professor Nicolas Doyon.
Treinamento em rede
Nos últimos anos, a inteligência artificial conseguiu alcançar grandes avanços graças ao desenvolvimento da aprendizagem profunda. “Agora trabalhamos com redes neurais com múltiplas camadas: a camada de entrada, as camadas intermediárias e a camada de saída. Entre um neurônio em uma camada e um neurônio em outra camada, existe uma força de conexão, também chamada de peso sináptico, e como a rede aprende, cada um deles é modificado.” Pesos”, observa Nicolas Doyon.
Como você aprende a rede? Pela formação, destaca a pesquisadora. Considere o caso de uma rede neural que é solicitada a confirmar se uma imagem é um gato ou um cachorro. Atribuiremos o valor 0 ao gato e 1 ao cachorro. Para treinar a rede, usaremos milhares, até milhões, de imagens dessas criaturinhas e examinaremos a porcentagem de imagens bem classificadas. Se a rede não der a resposta correta, ela não obterá o valor de saída correto porque os pesos intercalados não estão bem ajustados. Portanto, ajustaremos esses pesos até obtermos uma taxa de sucesso muito elevada.
Mas como ajusto os pesos? “Usamos, entre outras coisas, o método de descida gradiente. Para ilustrar isso, podemos imaginar uma pessoa tentando descer a encosta da montanha o mais rápido possível. Isso é fácil de visualizar quando há apenas duas entradas. No x- eixo, exibiremos a taxa de sucesso associada aos diferentes pesos que atingimos “Tem a primeira entrada, e no eixo y está a taxa de sucesso associada aos diferentes pesos pelos quais multiplicamos a segunda entrada. No eixo z. o erro aparecerá. É então possível visualizar o ponto onde o erro está mais baixo e tentar ajustar os pesos para avançar nessa direção”, explica o professor Doyon, que acrescenta ao mesmo tempo que o princípio, embora seja sempre iguais, é muito mais difícil de visualizar na realidade quando o número de parâmetros a serem ajustados está na casa dos milhões, ou mesmo bilhões.
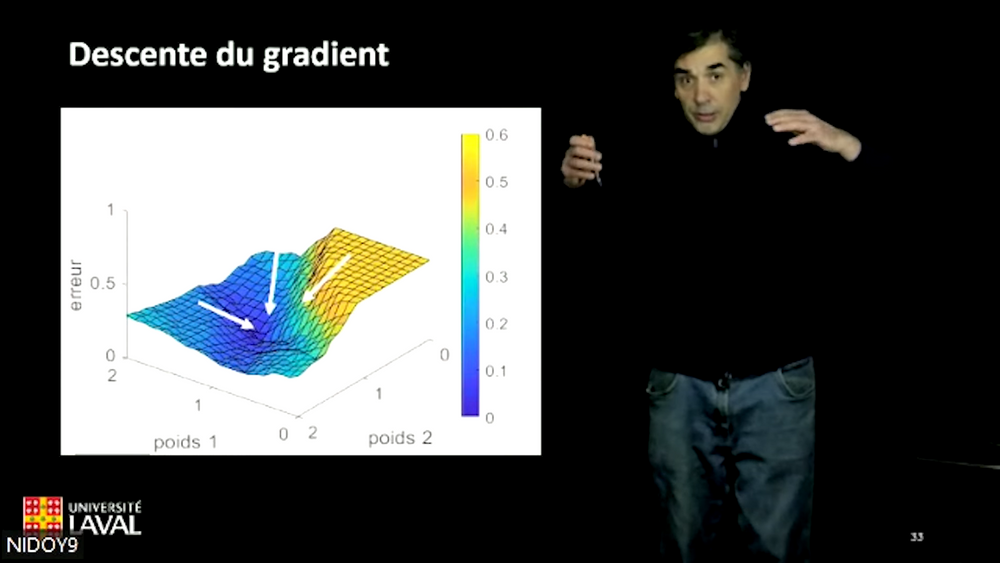
Ajustamos os pesos da malha usando o método de descida gradiente.
Matemática e leitura estão no centro do ChatGPT
É claro que os números exatos não foram revelados publicamente, mas podemos estimar que o ChatGPT possui uma rede de 60 a 80 bilhões de neurônios, 96 camadas e 175 bilhões de pesos que podem ser modificados. Para efeito de comparação, existem aproximadamente 85 bilhões de neurônios no cérebro humano. “A comparação ainda é um pouco tênue, porque nossos neurônios não são exatamente iguais aos neurônios artificiais, mas estamos aproximadamente na mesma ordem de grandeza”, concorda Nicolas Doyon.
Quando um aplicativo de computador é solicitado a se identificar, ele responde: “O ChatGPT usa uma arquitetura de rede neural profunda.” É importante observar que o ChatGPT não possui compreensão profunda ou autoconsciência. As respostas são baseadas apenas nas probabilidades estatísticas de palavras ou frases. Assim, para gerar texto, o ChatGPT irá calcular as chances de ele ser seguido por outra sequência de palavras, a partir de uma série de palavras, e então sugerir a sequência mais provável.
Para conseguir isso, o ChatGPT teve que treinar em bilhões de pontos de dados. O conteúdo desta leitura é, obviamente, confidencialidade profissional. No entanto, pode-se presumir que a rede foi treinada em mais de 300 bilhões de palavras. “Se você lesse 300 palavras por página e uma página por minuto, 24 horas por dia, teria que ler 1.900 anos para absorver essa quantidade de informação”, explica o matemático para ajudar a ter uma ideia do tamanho do biblioteca subjacente para aprender ChatGPT.
– Nicolas Doyon, sobre os 300 bilhões de palavras que supostamente compõem o banco de dados de treinamento ChatGPT
Entre admiração e medo
O incrível desempenho do ChatGPT às vezes desperta a imaginação de alguns, que veem o futuro como um filme de ficção científica onde a inteligência artificial domina o mundo. No entanto, este cenário não é o que preocupa aqueles, entre os cientistas, que gostariam de ver uma melhor regulamentação do desenvolvimento da IA. Em vez disso, o seu objectivo é evitar alguns dos deslizes associados à utilização que os humanos possam fazer deles. Eles também querem que dediquemos tempo para compreender e analisar melhor as ramificações negativas desta tecnologia.
“O que poderia dar errado? Obviamente, os estudantes podem usar o ChatGPT para trapacear. As pessoas podem perder seus empregos. Recentemente, escritores em greve em Hollywood exigiram limitar o uso de inteligência artificial na escrita de roteiros”, lembra Nicolas Doyon.
Além disso, o professor revela que outros problemas são menos óbvios e mais insidiosos. “Por exemplo, no campo do reconhecimento facial, a IA pode reconhecer homens brancos mais facilmente do que mulheres ou pessoas de minorias visíveis”, afirma. Este fato é um pouco surpreendente, pois imaginamos uma IA neutra. Não pode ser sexista ou racista. Mas como a IA provavelmente foi treinada em um banco de dados contendo mais rostos masculinos e brancos, ela herdou nossas falhas.
Outro exemplo que o professor dá vem do DeepL, um aplicativo de tradução que utiliza os mesmos princípios do ChatGPT. “Se pedirmos ao DeepL para traduzir a frase ‘ela lê’ para o húngaro, isso nos dará ‘ὄ olvassa’. Se pedirmos para traduzir as mesmas palavras húngaras para o francês, ele dirá ‘il lit’”, diz ele. Por que? Como o banco de dados tem viés estatístico, o sujeito masculino é frequentemente encontrado antes do verbo “ler”.
O problema ambiental, muitas vezes oculto, não deve ser encarado levianamente. “As pessoas pensam que a IA é virtual e não tem impacto no meio ambiente. Porém, de acordo com um artigo, cada vez que você fala com ela, o ChatGPT bebe 500ml de água. Esta imagem foi usada para nos lembrar que resfriar supercomputadores requer uma enorme quantidade de Água. Além desse recurso, o ChatGPT também requer muita energia. Alguns dizem que a IA em breve consumirá tanta eletricidade quanto um país inteiro.
Então, qual é o futuro da IA e do ChatGPT? “Não sei”, responde o professor Doyon humildemente. “Existem coisas que o ChatGPT nunca conseguirá fazer? Não tenho resposta. Todo mês ouvimos que o ChatGPT fez algo novo. É impossível saber onde tudo isso vai parar”, finaliza o matemático.
-
Para obter uma visão geral do negócio Nicolas Doyon
-
Saiba mais sobre reuniões anteriores e futuras Conferências gerais Organizado pela educação continuada na Faculdade de Ciências e Engenharia
-
Assista à conferência “ChatGPT Mathematical Secrets”:





